
AI Debate Experiment Architecture: Multi-Agent LLM Design
In the article AI Debate Experiment: Thinking and Persuasion, I talked about how I set two AI models against each other on a specific topic and what kind of results came out of it. In this post, I focus on the technical background of the experiment, in other words, how the system actually works.
I also made a few updates after the first post. I'll explain those changes and the reasons behind them here as well.
If you want to compare multiple models, make their outputs more meaningful, or generate synthetic data, the structure described in this experiment can be directly useful for you.
Overview
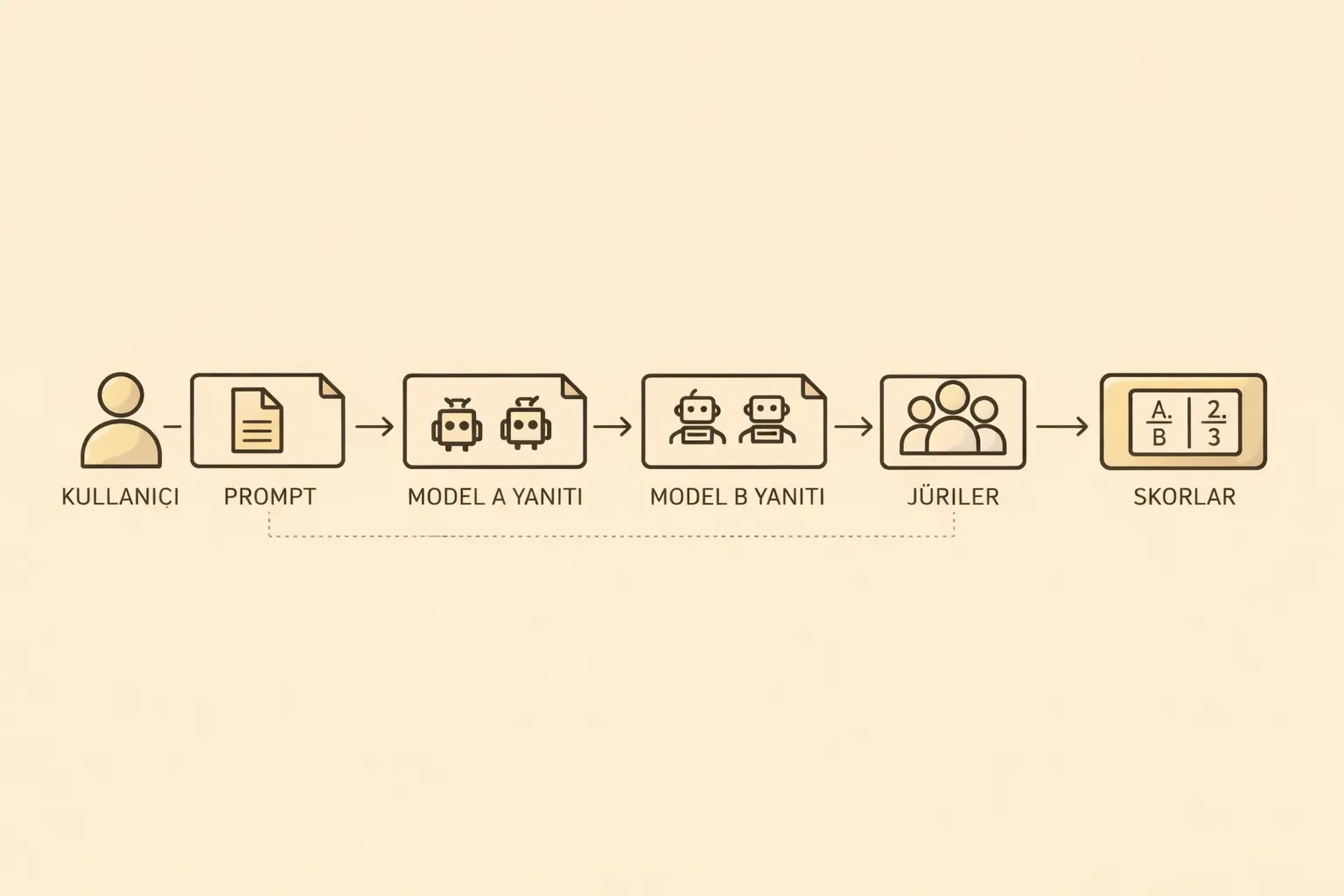
The flow of the experiment is quite simple:
- The user defines the topic and any additional conditions.
- Two different AI models are assigned as
Model AandModel B. - The models generate responses in rounds, based on their roles.
- The generated outputs are evaluated by one or more jury models.
- A winner is determined based on the jury scores.
Once I got into the details, a few small updates and differences appeared. Let's take a look at those now.
System Architecture and the Coordinator Structure
In the classic "prompt-response" setup, there are three roles: "user", "system", and "assistant". The "system" role defines how the model should behave, which rules it should follow, and its boundaries. The "user" role is the one that interacts with the model and provides inputs. Finally, the "assistant" role represents the model that generates output while taking the other two roles into account.
After understanding these roles and their definitions, I realized that showing the models as directly facing each other as "user" or "assistant" would not be correct for the experiment I had in mind. To solve this, I added an intermediary. This way, I designed a mediator structure that carries the other side's response inside the prompts exchanged between the two models.
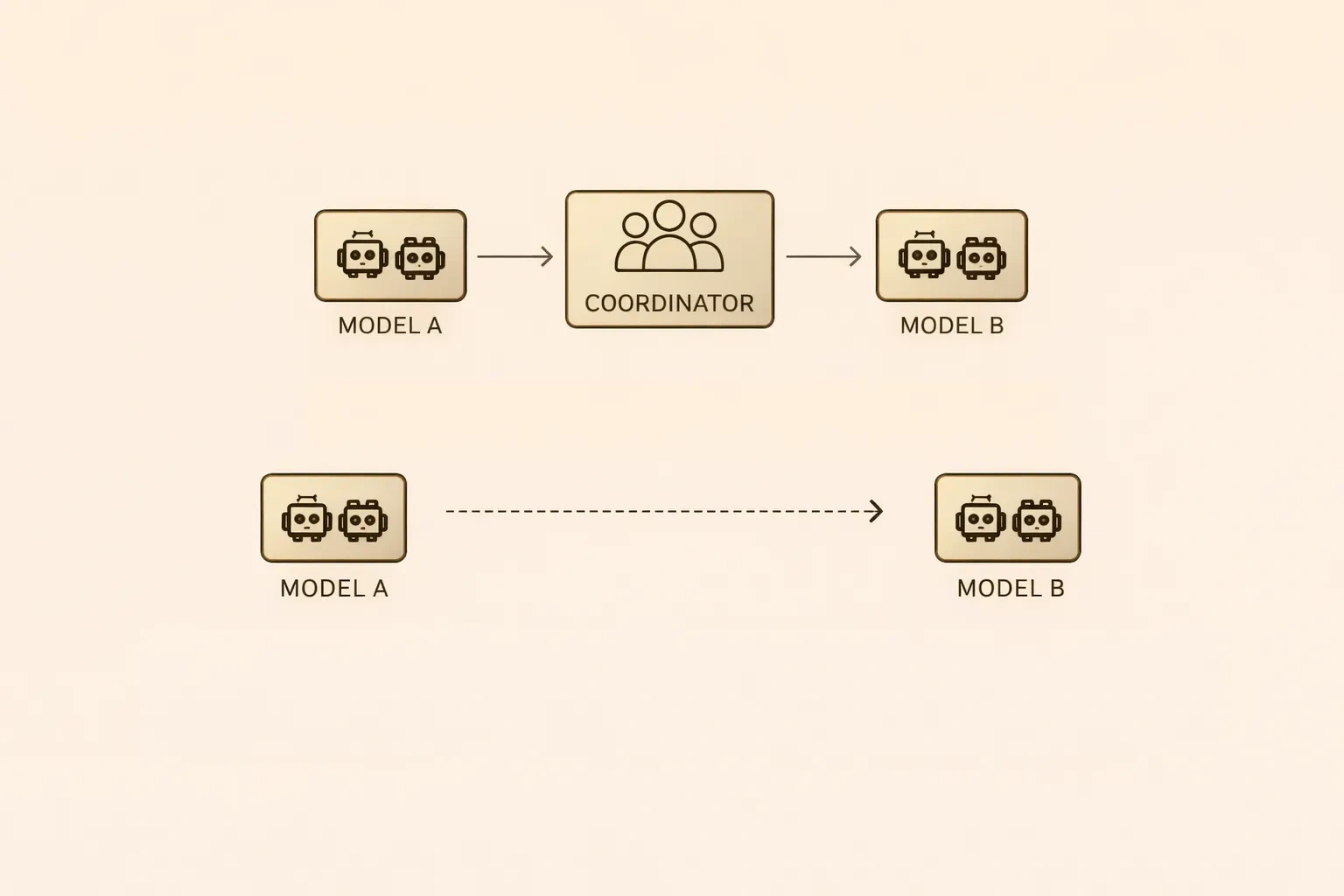
According to this setup:
round n
Coordinator -> Model A
Coordinator <- Model A
Coordinator -> Model B
Coordinator <- Model B
round n+1
Coordinator -> Model A (with Model B's response)
Coordinator <- Model A
Coordinator -> Model B (with Model A's response)
Coordinator <- Model B
This is the flow I designed.
Execution Flow and Code Structure
The code snippet below shows a simplified example of round-based coordination.
rounds = ["opening", "rebuttal", "assumptions", "closing"]
history_a, messages_a = [], []
history_b, messages_b = [], []
messages_a.append({"role": "system", "content": system_prompt})
messages_b.append({"role": "system", "content": system_prompt})
for i, round_name in enumerate(rounds, start=1):
# --- Model A ---
round_template_a = load_prompt(f"model_a/{round_name}")
from_b = history_b[i-2]["content"] if i > 1 else ""
variables_a = {
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
f"MODELB_ROUND_{i-1}": from_b
}
prompt_a = render_prompt(round_template_a, variables_a)
messages_a.append({"role": "user", "content": prompt_a})
result_a = call_model(client_a, model_a, messages_a)
history_a.append(result_a)
messages_a.append({"role": "assistant", "content": result_a["content"]})
# --- Model B ---
round_template_b = load_prompt(f"model_b/{round_name}")
from_a = history_a[i-1]["content"]
variables_b = {
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
f"MODELA_ROUND_{i}": from_a
}
prompt_b = render_prompt(round_template_b, variables_b)
messages_b.append({"role": "user", "content": prompt_b})
result_b = call_model(client_b, model_b, messages_b)
history_b.append(result_b)
messages_b.append({"role": "assistant", "content": result_b["content"]})This structure prevents the models from talking to each other directly and manages the entire interaction through the coordinator. In each round, only the output of the previous round is shared. This way, argument generation, rebuttals, and context control are fully handled at the application level.
Debate Rules and Constraints
In human debate competitions, there is usually a time limit. When the topic is AI, I needed to adjust these rules a bit. First, I added a word limit. I set a rule that each model can use at most 500 words, except for the final round. In addition, by limiting them to a maximum of 3 arguments, I aimed to avoid possible unfairness between the models.
In the final round, I asked them to produce a synthesis within 500 characters. On top of that, I asked them to explain their final decision in 200 words.
The goal of these rules is not to restrict the models, but to make the generated arguments comparable. That's why there will likely be different rules as the experiment is repeated.
Model Roles
From the very beginning of the experiment, the only thing that has stayed constant is that there are two AI models: one defends the given thesis, and the other opposes or criticizes it. I tried to keep these roles fixed throughout the experiment and made sure all messaging was handled through the coordinating code.
Jury Mechanism and Blind Evaluation
To ensure an unbiased evaluation, I chose to create a completely separate prompt for the jury models and to send a single request for each jury without keeping any history. Since the jury has no memory in this setup, I assumed it would make a more neutral judgment.
judge_template = load_prompt("judge/judge")
model_a_text = merge_responses(history_a)
model_b_text = merge_responses(history_b)
rendered_prompt = render_prompt(
judge_template,
{
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
"MODEL_A_TEXT": model_a_text,
"MODEL_B_TEXT": model_b_text,
},
)
messages = [
{"role": "system", "content": "You are a neutral debate judge."},
{"role": "user", "content": rendered_prompt},
]
result = call_model(client, judge_model, messages)While testing this, I noticed that under certain topics, the same model kept winning. To address this, I added a blind evaluation mechanism where I swap the model names (by swapping model codes). The idea was to push the jury to focus more on the quality of the arguments rather than the model identity.
The jury setup allows for one or more juries. Each jury has its own separate session and messages, so they do not influence each other.
Configuration and Parametric Structure
After running the experiment multiple times on the same topic, I tried to make the setup more flexible by turning it into a more parametric structure. The code I wrote for the experiment now runs fully parametrically through a .env file.
API_KEY=YOUR_OPENROUTER_KEY
TOPIC="Remote work is more productive than working from an office."
# CONDITIONS is optional. Leave empty to apply no extra constraints.
CONDITIONS="Consider only the conditions in Turkey (Türkiye)."
LANG_CODE=tr
LOCAL_BASE_URL=http://localhost:1234/v1
ONLINE_BASE_URL=https://openrouter.ai/api/v1
MODEL_A_BACKEND=local
MODEL_A_MODEL=local-model-a
MODEL_B_BACKEND=online
MODEL_B_MODEL=deepseek/deepseek-v3.2
JUDGE_BACKENDS=online,online
JUDGE_MODELS=openai/gpt-5.2,deepseek/deepseek-v3.2
JUDGE_BLIND=trueInfrastructure Choices
Even though my original goal was different, I wanted to try as many models as possible at a low cost. That's why I first started with local models using LM Studio. However, due to my computer's limited resources, I connected Open Router to the code, which allowed me to access more models while spending less money.
Closing Notes
In this post, I tried to share the technical decisions behind how I designed the experiment. So far, on 2 English and 1 Turkish topics, 15 online and 3 local models have competed against each other in nearly a thousand debates. Across all these runs, 14.5 million tokens were sent to the models, and 20.3 million tokens were received in return. The total cost of this entire operation was around 35 USD.
For future debates, I'd appreciate it if you could send topic and model suggestions. Below, you'll find the models and topics that have worked so far.
I will start evaluating and interpreting the results and sharing the outputs. If possible, I'm also thinking about setting up a structure where humans can evaluate the outputs as well. This way, I aim to label and put the generated synthetic data into use.
Finally, you can visit the experiment's code repository on GitHub. You can download it and run it yourself.
Technical Takeaways
With this experiment, I learned and experienced how to design a setup where two models debate each other. I also learned what I can do to ensure model neutrality.
I think there is still room to improve the experiment. For example, making some requests run in parallel. Your knowledge sharing would be very valuable here. Especially if you have suggestions around different jury approaches or round designs, I'd be glad to hear them.
Topics
So far, the topics I planned for the experiment are listed below. I chose them because I believe they can create a proper debate environment and allow for strong arguments. I also tried running the experiment in different languages to measure the models' reasoning and logic capabilities.
- AI will eventually replace most software developers.
- Remote work is more productive than working from an office. (Consider only the conditions in Turkey (Türkiye).)
- Learning core fundamentals deeply is more valuable than keeping up with fast-changing tools and technologies.
- In the long run, communication skills are more valuable than technical expertise. (Not done yet)
- Relying on AI tools makes professionals less competent over time. (Planned)
- Data-driven decision making produces better outcomes than intuition-based decision making. (Planned)
- Shipping fast is more important than building high-quality solutions. (Planned)
Models
In the list below, you can find the models I used as debaters and jury models in the experiment. I selected this list by looking at trends on Open Router. For local models, I chose based on my machine's capacity.
- anthropic/claude-opus-4.5
- deepseek/deepseek-v3.2
- openai/gpt-5.2
- minimax/minimax-m2.1
- openai/gpt-oss-120b
- qwen/qwen3-max
- meta-llama/llama-3.3-70b-instruct
- anthropic/claude-haiku-4.5
- x-ai/grok-4.1-fast
- anthropic/claude-sonnet-4.5
- xiaomi/mimo-v2-flash:free
- google/gemini-2.5-flash
- google/gemini-3-flash-preview
- z-ai/glm-4.7
- mistralai/devstral-2512:free
- microsoft/phi-4
- google/gemma-3-12b
- ibm/granite-3.2-8b