
Yapay Zekâ Münazara Deneyi: Teknik Arka Plan
Yapay Zeka ile Münazara Deneyi: Düşünme ve İkna yazısında iki yapay zeka modelini belirli bir konu üzerinden nasıl karşı karşıya getirdiğimden ve ortaya çıkan sonuçlardan bahsetmiştim. Bu yazıda ise deneyin teknik arka planına, yani sistemin nasıl çalıştığına odaklanıyorum.
İlk yazıda anlattığımın üstüne birkaç güncelleme de yaptım, onları da sebepleriyle bu yazı içinde anlatıyor olacağım.
Eğer birden fazla modeli karşılaştırmak, çıktıları anlamlı hâle getirmek veya sentetik veri üretmek istiyorsanız, bu deneyde anlatılan yapı doğrudan işinize yarayacaktır.
Genel Bakış
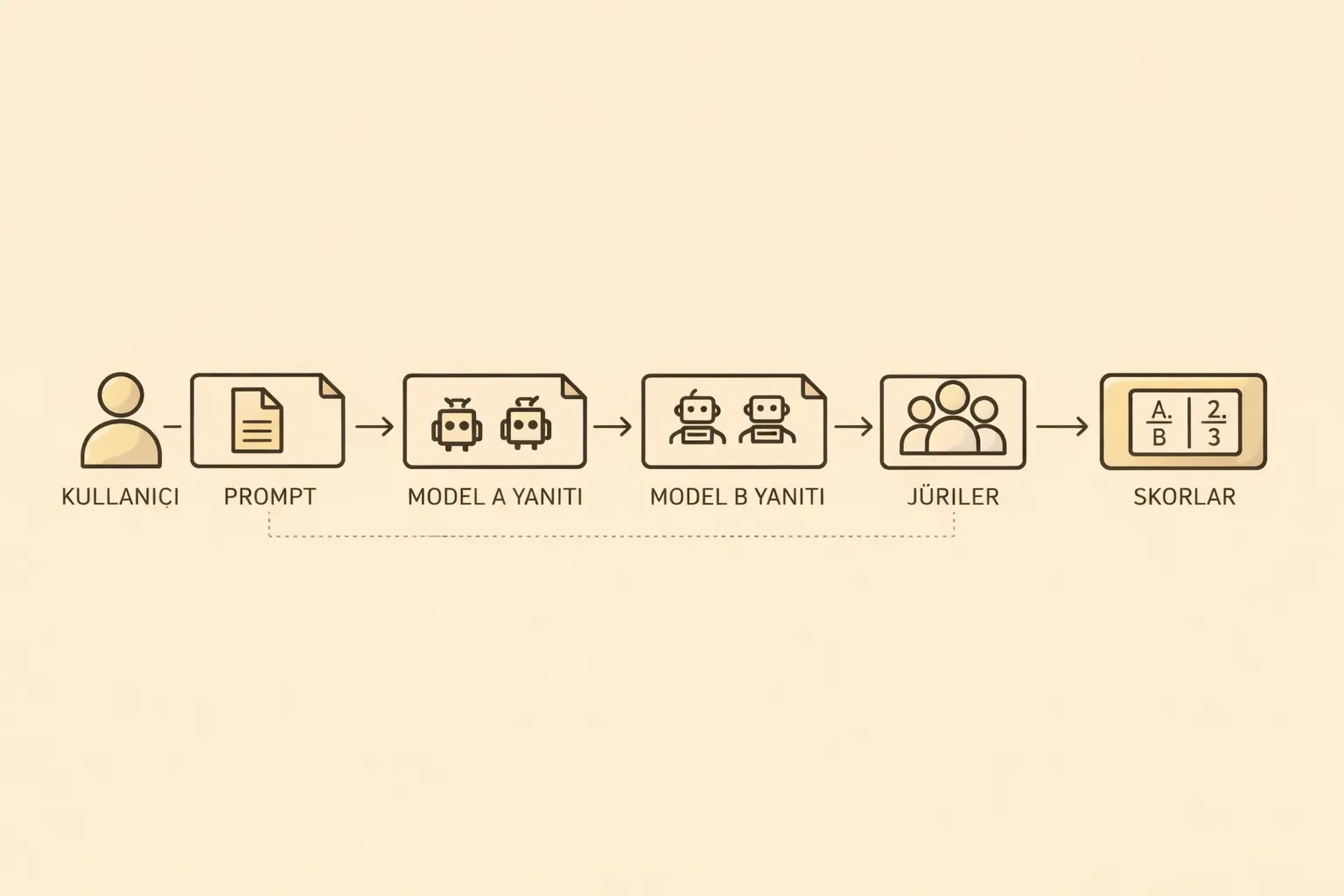
Deneyin akışı oldukça basit;
- Kullanıcı konu ve varsa ek koşulları belirler.
- İki farklı yapay zeka modeli
Model AveModel Bolarak atanır. - Modeller, rollerine göre turlar halinde yanıt üretir.
- Üretilen çıktılar, bir veya daha fazla jüri modeli tarafından değerlendirilir.
- Jüri skorlarına göre kazanan belirlenir.
Ancak işin içine girince bazı ufak güncellemeler ve farklılıklar ortaya çıktı; şimdi onlara bakacağız.
Sistem Mimarisi ve Koordinatör Yapısı
Klasik "prompt - cevap" yapısında üç tane rol vardır; "user", "system" ve "assistant". "system" rolü modelin nasıl davranacağını, hangi kurallara uyacağını ve sınırlarını belirler. "user" rolü model ile etkileşime giren ve girdileri veren roldür. Son olarak "assistant" rolü de diğer iki rolü dikkate alarak çıktı üreten modeli ifade eder.
Rollerin detaylarını ve tanımlarını öğrenince benim planladığım deney için modelleri karşılıklı "user" veya "assistant" olarak göstermenin doğru olmayacağını gördüm. Bu durumu çözmek için araya bir aracı ekledim. Bu sayede iki model arasında promptlara diğer tarafında cevabını taşıyan bir aracı yapı kurguladım.
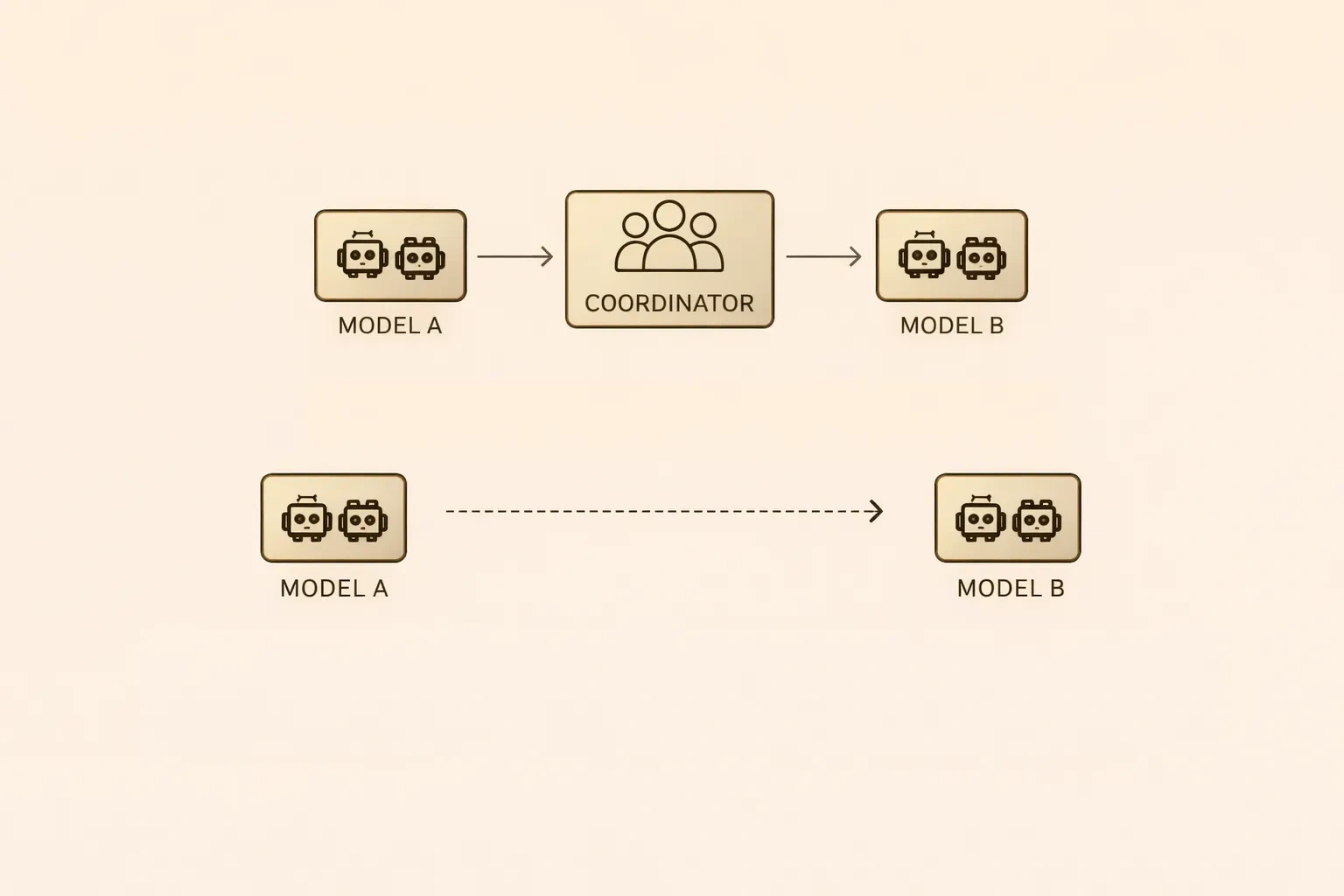
Bu kurguya göre;
n. tur Koordinatör -> Model A Koordinatör <- Model A Koordinatör -> Model B Koordinatör <- Model B
n+1. tur Koordinatör -> Model A (Model B'nin cevabı ile) Koordinatör <- Model A Koordinatör -> Model B (Model A'nın cevabı ile) Koordinatör <- Model B
şeklinde bir akış tasarladım.
Uygulama Akışı ve Kod Yapısı
Aşağıdaki kod parçası, tur bazlı koordinasyonun sadeleştirilmiş bir örneğini gösterir.
rounds = ["opening", "rebuttal", "assumptions", "closing"]
history_a, messages_a = [], []
history_b, messages_b = [], []
messages_a.append({"role": "system", "content": system_prompt})
messages_b.append({"role": "system", "content": system_prompt})
for i, round_name in enumerate(rounds, start=1):
# --- Model A ---
round_template_a = load_prompt(f"model_a/{round_name}")
from_b = history_b[i-2]["content"] if i > 1 else ""
variables_a = {
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
f"MODELB_ROUND_{i-1}": from_b
}
prompt_a = render_prompt(round_template_a, variables_a)
messages_a.append({"role": "user", "content": prompt_a})
result_a = call_model(client_a, model_a, messages_a)
history_a.append(result_a)
messages_a.append({"role": "assistant", "content": result_a["content"]})
# --- Model B ---
round_template_b = load_prompt(f"model_b/{round_name}")
from_a = history_a[i-1]["content"]
variables_b = {
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
f"MODELA_ROUND_{i}": from_a
}
prompt_b = render_prompt(round_template_b, variables_b)
messages_b.append({"role": "user", "content": prompt_b})
result_b = call_model(client_b, model_b, messages_b)
history_b.append(result_b)
messages_b.append({"role": "assistant", "content": result_b["content"]})Bu yapı, modellerin doğrudan konuşmasını engelleyerek tüm etkileşimi koordinatör üzerinden yönetir. Her turda yalnızca bir önceki turun çıktısı paylaşılır; böylece argüman üretimi, çürütme ve bağlam kontrolü tamamen uygulama seviyesinde sağlanır.
Münazara Kuralları ve Kısıtlar
İnsanların karşılıklı yaptığı münazara yarışmalarında genellikle süre sınırı kuralı vardır. Ancak konu yapay zeka olunca bu kuralları biraz güncellemem gerekti. Öncelikle kelime sınırı ekledim. Her model son tur hariç en fazla 500 kelime kullanabilir kuralı getirdim. Bunun yanında en fazla 3 argüman üretebileceklerini de belirterek modellerin arasında oluşabilecek adaletsizliğin de önüne geçmeyi hedefledim.
Son turda 500 karakter ile bir sentez çıkartmalarını istedim. Ek olarak ta en son kararlarını 200 kelime ile anlatmalarını istedim.
Bu kuralların amacı modelleri kısıtlamak değil, üretilen argümanların karşılaştırılabilir olmasını sağlamak. O yüzden deney tekrarlandıkça daha farklı kurallar olacaktır.
Model Rolleri
Deneyin en başından beri belirlenmiş olan ve değişmeyen tek şey iki tane yapay zeka modeli olacağı ve birinin verilen tezi savunurken diğerinin aynı teze karşı çıkan veya eleştiren taraf olması. Modellerin rollerini deney boyunca hep sabit ve mesajlaşmalarını koordine eden kod üzerinden yürütmelerini sağlamaya çalıştım.
Jüri Mekanizması ve Kör Değerlendirme
Tarafsız bir değerlendirme yapmak için, jüri modelleri için tamamen ayrı bir prompt oluşturmayı ve her bir jüri için history tutmadan tek bir istek atma şeklinde ilerlemeyi seçtim. Bu sayede jürinin hafızasında herhangi bir bilgi olmadığı için tarafsız bir değerlendirme yapacağını düşündüm.
judge_template = load_prompt("judge/judge")
model_a_text = merge_responses(history_a)
model_b_text = merge_responses(history_b)
rendered_prompt = render_prompt(
judge_template,
{
"TOPIC": topic,
"CONDITIONS": conditions,
"LANG": lang,
"MODEL_A_TEXT": model_a_text,
"MODEL_B_TEXT": model_b_text,
},
)
messages = [
{"role": "system", "content": "You are a neutral debate judge."},
{"role": "user", "content": rendered_prompt},
]
result = call_model(client, judge_model, messages)Bunu test ederken bir başlıkta hep bir modelin kazandığını görünce modellerin isimlerini değiştirebileceğim bir kör değerlendirme mekanizması (model kodlarını swap ediyorum) ekleyerek daha çok üretilen argümanların kalitesine odaklanmalarını sağlamaya çalıştım.
Jüri değerlendirmesinde 1 veya daha fazla jüri olabilir şekilde tasarlandı. Her jürinin ayrı birer oturumu ve mesajı oluyor. Bu sayede jüriler de birbirlerinden etkilenmemiş oluyorlar.
Konfigürasyon ve Parametrik Yapı
Deneyin aynı konu için birkaç kez çalıştırdıktan sonra daha parametrik yaparak daha esnek bir yapı kurmaya çalıştım. Deney için yazdığım kod .env dosyası üzerinden tamamen parametrik olarak çalışabiliyor şu anda.
API_KEY=YOUR_OPENROUTER_KEY
TOPIC="Remote work is more productive than working from an office."
# CONDITIONS is optional. Leave empty to apply no extra constraints.
CONDITIONS="Consider only the conditions in Turkey (Türkiye)."
LANG_CODE=tr
LOCAL_BASE_URL=http://localhost:1234/v1
ONLINE_BASE_URL=https://openrouter.ai/api/v1
MODEL_A_BACKEND=local
MODEL_A_MODEL=local-model-a
MODEL_B_BACKEND=online
MODEL_B_MODEL=deepseek/deepseek-v3.2
JUDGE_BACKENDS=online,online
JUDGE_MODELS=openai/gpt-5.2,deepseek/deepseek-v3.2
JUDGE_BLIND=trueAltyapı Tercihleri
Deneyi yaparken amacım farklı olsa da olabildiğince çok modeli daha az maliyetle denemek istiyordum. O yüzden ilk olarak LM Studio üzerinden yerel modeller ile çalışmaya başladım. Ancak bilgisayarımın kısıtlı kaynaklarından dolayı, az para harcayarak daha çok modele ulaşmamı sağlayan Open Router'ı koda bağlamış oldum.
Kapanış Sözü
Bu yazıda, deneyi hangi teknik kararlarla kurguladığımı paylaşmaya çalıştım. Şu ana kadar 2 İngilizce ve 1 Türkçe konu başlığında, 15 online ve 3 yerel modeli karşılıklı olarak bine yakın yarışma yaptılar. Bu yarışmaların toplamında 14.5 Milyon token modellere gitti, 20.3 milyon token geldi. Bütün bu operasyon için 35 USD gibi bir harcama yapmış oldum.
Yeni yarışmalar yapmak için konu ve model önerisi göndermenizi rica ediyorum. Aşağıda şu ana kadar çalışan modeller ve konuları bulacaksınız.
Sonuçların değerlendirilmesi ve yorumlanmasına başlayacağım ve çıktıları da paylaşacağım. Hatta yapabilirsem, çıktıların insanlar tarafından da değerlendirilmesi için bir yapı kurmayı düşünüyorum. Bu sayede üretilen sentetik veriyi de işaretleyerek kullanıma sokabilmeyi hedefliyorum.
Son olarak deney kodunun GitHub reposunu ziyaret edebilir. İndirip çalıştırabilirsiniz.
Teknik Çıkarımlar
Bu deney ile iki modelin karşılıklı konuşturulma kurgusunu öğrenmiş ve deneyimlemiş oldum. Ek olarak modellerin tarafsızlığını sağlamak için neler yapabileceğimi öğrenmiş oldum.
Deneyin hâlâ geliştirecek yerleri olduğunu düşünüyorum. Örneğin; bazı istekleri paralel yapmak gibi. Bunun için sizlerin bilgi paylaşımı çok değerli olacaktır. Özellikle farklı jüri yaklaşımları veya tur kurguları konusunda önerileriniz varsa paylaşmanızı isterim.
Konu Başlıkları
Şu ana kadar deney için planladığım konu başlıkları aşağıdaki gibidir. Bu başlıkları karşılıklı tartışma ortamı yaratabilmek ve argüman üretebileceklerini düşündüğüm için seçtim. Farklı dillerde de deneyerek modellerin çıkarım ve mantık kapasitelerini ölçmeye çalıştım.
- AI will eventually replace most software developers.
- Remote work is more productive than working from an office. (Consider only the conditions in Turkey (Türkiye).)
- Temel bilgileri derinlemesine öğrenmek, hızla değişen araç ve teknolojileri takip etmekten daha değerlidir.
- Uzun vadede iletişim becerileri, teknik uzmanlıktan daha değerlidir. (Daha yapılmadı sırada)
- Yapay zekâ araçlarına güvenmek, profesyonelleri zamanla daha az yetkin hâle getirir. (Daha yapılması sırada)
- Data-driven decision making produces better outcomes than intuition-based decision making. (Daha yapılması sırada)
- Shipping fast is more important than building high-quality solutions. (Daha yapılması sırada)
Modeller
Aşağıdaki listede deney içinde model ve jüri modeli olarak kullandığım ürünleri bulacaksınız. Bu listeyi Open Router üzerindeki trendlere bakarak belirledim. Yerel modelleri de bilgisayarımın kapasitesine göre belirlemeyi tercih ettim.
- anthropic/claude-opus-4.5
- deepseek/deepseek-v3.2
- openai/gpt-5.2
- minimax/minimax-m2.1
- openai/gpt-oss-120b
- qwen/qwen3-max
- meta-llama/llama-3.3-70b-instruct
- anthropic/claude-haiku-4.5
- x-ai/grok-4.1-fast
- anthropic/claude-sonnet-4.5
- xiaomi/mimo-v2-flash:free
- google/gemini-2.5-flash
- google/gemini-3-flash-preview
- z-ai/glm-4.7
- mistralai/devstral-2512:free
- microsoft/phi-4
- google/gemma-3-12b
- ibm/granite-3.2-8b